- Sep 11, 2024
Flink : Writing your first program
- DevTechie Inc
In our last article we learned how to install flink, troubleshoot problems on the way and executing your first program from the example set.
In this article we will go into very basics and write the same wordcount program, build the jar file and execute the script. This article is for someone who is a complete beginner, intermediate to advanced programmers can skip certain parts. So, let’s get started.
What you will need?
IntelliJ IDE
Maven installed
JAVA 11 or 8 (Java 8 is deprecated so Java 11 is preferred)
First we need an IDE, I am using IntelliJ Community version and for building our project I am using Maven.
Note: Below steps are executed on a Mac, for windows same can be done using Cygwin.
First step, in order to create a project we will use Archetype with Maven as below. Open up your terminal and navigate to the directory where you want to create your project, thereafter run below:
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.20.0Note: Install maven if it is not installed.
This will ask for groupId, artifactId, version and package as below
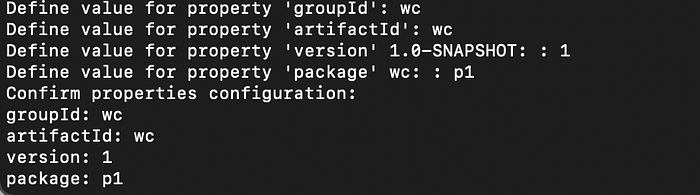
As you can see above, I am naming my groupId as “wc” , artifactId as “wc”, version 1 and package as “p1”. But you can give whatever name you like, make sure to change accordingly in your program which we will see shortly.
Once above step is complete you should see “Build Success” as below:

Now, we will fire up our IntelliJ and open up the project we just created above.
It will ask for a project name, in my case I am keeping it short and simple as below
Once project is imported in IntelliJ, you should see below:
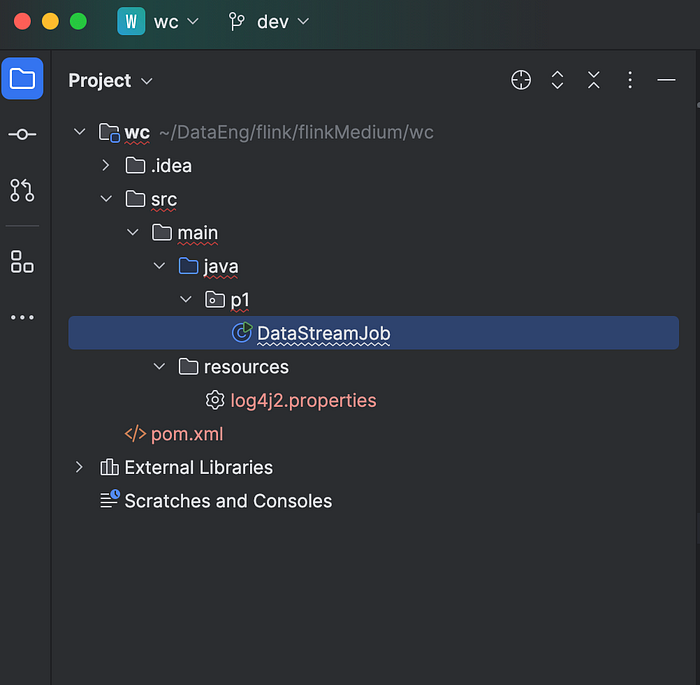
We will go ahead and refactor the class file and rename to WordCount as below:

In order to manage our dependencies, we will update our pom.xml file. This pom.xml contains the configuration details used by Maven to build the project. Project’s dependencies, plugins can be specified under this pom.xml and it is crucial while working with build tool like Maven.
Our pom.xml file would look like below
<!--
Licensed to the Apache Software Foundation (ASF) under one
or more contributor license agreements. See the NOTICE file
distributed with this work for additional information
regarding copyright ownership. The ASF licenses this file
to you under the Apache License, Version 2.0 (the
"License"); you may not use this file except in compliance
with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing,
software distributed under the License is distributed on an
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
KIND, either express or implied. See the License for the
specific language governing permissions and limitations
under the License.
-->
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>wc</groupId>
<artifactId>wc</artifactId>
<version>1</version>
<packaging>jar</packaging>
<name>Flink Quickstart Job</name>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.20.0</flink.version>
<target.java.version>1.8</target.java.version>
<scala.binary.version>2.12</scala.binary.version>
<maven.compiler.source>${target.java.version}</maven.compiler.source>
<maven.compiler.target>${target.java.version}</maven.compiler.target>
<log4j.version>2.17.1</log4j.version>
</properties>
<repositories>
<repository>
<id>apache.snapshots</id>
<name>Apache Development Snapshot Repository</name>
<url>https://repository.apache.org/content/repositories/snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
<dependencies>
<!-- Apache Flink dependencies -->
<!-- These dependencies are provided, because they should not be packaged into the JAR file. -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-avro</artifactId>
<version>1.13.6</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-files -->
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-files -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>1.20.0</version>
<scope>provided</scope>
</dependency>
<!-- Add connector dependencies here. They must be in the default scope (compile). -->
<!-- Example:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>3.0.0-1.17</version>
</dependency>
-->
<!-- Add logging framework, to produce console output when running in the IDE. -->
<!-- These dependencies are excluded from the application JAR by default. -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>${target.java.version}</source>
<target>${target.java.version}</target>
</configuration>
</plugin>
<!-- We use the maven-shade plugin to create a fat jar that contains all necessary dependencies. -->
<!-- Change the value of <mainClass>...</mainClass> if your program entry point changes. -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<!-- Run shade goal on package phase -->
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
<artifactSet>
<excludes>
<exclude>org.apache.flink:flink-shaded-force-shading</exclude>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>org.apache.logging.log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>p1.DataStreamJob</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
<pluginManagement>
<plugins>
<!-- This improves the out-of-the-box experience in Eclipse by resolving some warnings. -->
<plugin>
<groupId>org.eclipse.m2e</groupId>
<artifactId>lifecycle-mapping</artifactId>
<version>1.0.0</version>
<configuration>
<lifecycleMappingMetadata>
<pluginExecutions>
<pluginExecution>
<pluginExecutionFilter>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<versionRange>[3.1.1,)</versionRange>
<goals>
<goal>shade</goal>
</goals>
</pluginExecutionFilter>
<action>
<ignore/>
</action>
</pluginExecution>
<pluginExecution>
<pluginExecutionFilter>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<versionRange>[3.1,)</versionRange>
<goals>
<goal>testCompile</goal>
<goal>compile</goal>
</goals>
</pluginExecutionFilter>
<action>
<ignore/>
</action>
</pluginExecution>
</pluginExecutions>
</lifecycleMappingMetadata>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>Some of the dependencies that would be needed for this projects (as can be seen above) are “flink-streaming-java”, “flink-clients” and “flink-connector-files”.
We will need 3 class files for this project
a. WordCount.java (as created above)
b. CLI.java
So let’s create these 3 classes and we will understand the operation after that.
package p1;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.MemorySize;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.connector.file.src.FileSource;
import org.apache.flink.connector.file.src.reader.TextLineInputFormat;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import org.apache.flink.util.Collector;
import java.time.Duration;
public class WordCount {
public static void main(String[] args) throws Exception {
final CLI params = CLI.fromArgs(args);
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(params.getExecutionMode());
env.getConfig().setGlobalJobParameters(params);
DataStream<String> text;
if (params.getInputs().isPresent()) {
FileSource.FileSourceBuilder<String> builder =
FileSource.forRecordStreamFormat(
new TextLineInputFormat(), params.getInputs().get());
params.getDiscoveryInterval().ifPresent(builder::monitorContinuously);
text = env.fromSource(builder.build(), WatermarkStrategy.noWatermarks(), "file-input");
} else {
text = env.fromData(WordCountData.WORDS).name("in-memory-input");
}
DataStream<Tuple2<String, Integer>> counts =
text.flatMap(new Tokenizer())
.name("tokenizer")
.keyBy(value -> value.f0)
.sum(1)
.name("counter");
if (params.getOutput().isPresent()) {
counts.sinkTo(
FileSink.<Tuple2<String, Integer>>forRowFormat(
params.getOutput().get(), new SimpleStringEncoder<>())
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withMaxPartSize(MemorySize.ofMebiBytes(1))
.withRolloverInterval(Duration.ofSeconds(10))
.build())
.build())
.name("file-sink");
} else {
counts.print().name("print-sink");
}
env.execute("WordCount");
}
public static final class Tokenizer
implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
String[] tokens = value.toLowerCase().split("\\W+");
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<>(token, 1));
}
}
}
}
}package p1;
import org.apache.flink.api.common.ExecutionConfig;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.java.utils.MultipleParameterTool;
import org.apache.flink.configuration.ExecutionOptions;
import org.apache.flink.core.fs.Path;
import org.apache.flink.util.TimeUtils;
import java.time.Duration;
import java.util.Arrays;
import java.util.Map;
import java.util.Objects;
import java.util.Optional;
import java.util.OptionalInt;
public class CLI extends ExecutionConfig.GlobalJobParameters {
public static final String INPUT_KEY = "input";
public static final String OUTPUT_KEY = "output";
public static final String DISCOVERY_INTERVAL = "discovery-interval";
public static final String EXECUTION_MODE = "execution-mode";
public static CLI fromArgs(String[] args) throws Exception {
MultipleParameterTool params = MultipleParameterTool.fromArgs(args);
Path[] inputs = null;
if (params.has(INPUT_KEY)) {
inputs =
params.getMultiParameterRequired(INPUT_KEY).stream()
.map(Path::new)
.toArray(Path[]::new);
} else {
System.out.println("Executing example with default input data.");
System.out.println("Use --input to specify file input.");
}
Path output = null;
if (params.has(OUTPUT_KEY)) {
output = new Path(params.get(OUTPUT_KEY));
} else {
System.out.println("Printing result to stdout. Use --output to specify output path.");
}
Duration watchInterval = null;
if (params.has(DISCOVERY_INTERVAL)) {
watchInterval = TimeUtils.parseDuration(params.get(DISCOVERY_INTERVAL));
}
RuntimeExecutionMode executionMode = ExecutionOptions.RUNTIME_MODE.defaultValue();
if (params.has(EXECUTION_MODE)) {
executionMode = RuntimeExecutionMode.valueOf(params.get(EXECUTION_MODE).toUpperCase());
}
return new CLI(inputs, output, watchInterval, executionMode, params);
}
private final Path[] inputs;
private final Path output;
private final Duration discoveryInterval;
private final RuntimeExecutionMode executionMode;
private final MultipleParameterTool params;
private CLI(
Path[] inputs,
Path output,
Duration discoveryInterval,
RuntimeExecutionMode executionMode,
MultipleParameterTool params) {
this.inputs = inputs;
this.output = output;
this.discoveryInterval = discoveryInterval;
this.executionMode = executionMode;
this.params = params;
}
public Optional<Path[]> getInputs() {
return Optional.ofNullable(inputs);
}
public Optional<Duration> getDiscoveryInterval() {
return Optional.ofNullable(discoveryInterval);
}
public Optional<Path> getOutput() {
return Optional.ofNullable(output);
}
public RuntimeExecutionMode getExecutionMode() {
return executionMode;
}
public OptionalInt getInt(String key) {
if (params.has(key)) {
return OptionalInt.of(params.getInt(key));
}
return OptionalInt.empty();
}
@Override
public Map<String, String> toMap() {
return params.toMap();
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
if (!super.equals(o)) {
return false;
}
CLI cli = (CLI) o;
return Arrays.equals(inputs, cli.inputs)
&& Objects.equals(output, cli.output)
&& Objects.equals(discoveryInterval, cli.discoveryInterval);
}
@Override
public int hashCode() {
int result = Objects.hash(output, discoveryInterval);
result = 31 * result + Arrays.hashCode(inputs);
return result;
}
}package p1;
public class WordCountData {
public static final String[] WORDS =
new String[] {
"To be, or not to be,--that is the question:--",
"Whether 'tis nobler in the mind to suffer",
"The slings and arrows of outrageous fortune",
"Or to take arms against a sea of troubles,",
"And by opposing end them?--To die,--to sleep,--",
"No more; and by a sleep to say we end",
"The heartache, and the thousand natural shocks",
"That flesh is heir to,--'tis a consummation",
"Devoutly to be wish'd. To die,--to sleep;--",
"To sleep! perchance to dream:--ay, there's the rub;",
"For in that sleep of death what dreams may come,",
"When we have shuffled off this mortal coil,",
"Must give us pause: there's the respect",
"That makes calamity of so long life;",
"For who would bear the whips and scorns of time,",
"The oppressor's wrong, the proud man's contumely,",
"The pangs of despis'd love, the law's delay,",
"The insolence of office, and the spurns",
"That patient merit of the unworthy takes,",
"When he himself might his quietus make",
"With a bare bodkin? who would these fardels bear,",
"To grunt and sweat under a weary life,",
"But that the dread of something after death,--",
"The undiscover'd country, from whose bourn",
"No traveller returns,--puzzles the will,",
"And makes us rather bear those ills we have",
"Than fly to others that we know not of?",
"Thus conscience does make cowards of us all;",
"And thus the native hue of resolution",
"Is sicklied o'er with the pale cast of thought;",
"And enterprises of great pith and moment,",
"With this regard, their currents turn awry,",
"And lose the name of action.--Soft you now!",
"The fair Ophelia!--Nymph, in thy orisons",
"Be all my sins remember'd."
};
}Under IntelliJ it should look as below:
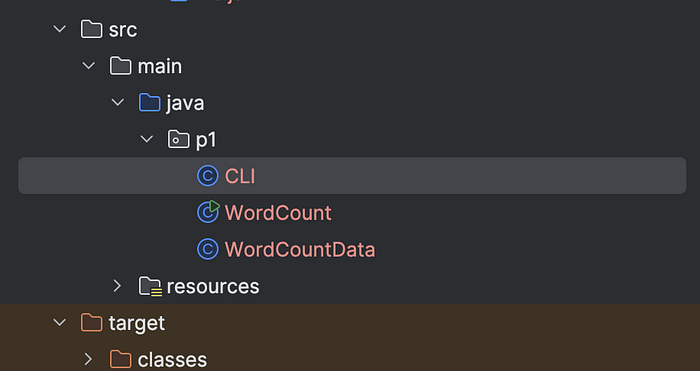
Understanding the code
Now let’s understand what this code is doing starting with WordCount.java.
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamExecutionEnvironment is used with DataStreamAPI and is the context in which a streaming program is executed. Other examples of StreamEnvironment are LocalStreamEnvironment and RemoteStreamEnvironment. The environment provides methods to control the job execution such as setting the parallelism or the fault tolerance/checkpointing parameters etc... Any flink application would need an ExecutionEnvironment.
env.setRuntimeMode(params.getExecutionMode());There are different runtime execution modes that are supported
STREAMING: The classic DataStream execution mode (default)BATCH: Batch-style execution on the DataStream APIAUTOMATIC: Let the system decide based on the boundedness of the sources. Flink will set the execution mode toBATCHif all sources are bounded, orSTREAMINGif there is at least one source which is unbounded.
It is recommended and good practice to provide this as an argument from CLI. Default value is Streaming and among different things, this controls task scheduling, network shuffle behavior, and time semantics.
env.getConfig().setGlobalJobParameters(params);Parameters registered as global job parameters in the ExecutionConfig can be accessed as configuration values from the JobManager web interface and in all functions defined by the user. Thereby, setting this will have input parameters available in the Flink UI
DataStream<String> text;
if (params.getInputs().isPresent()) {
text = env.fromSource(builder.build(), WatermarkStrategy.noWatermarks(), "file-input");
} else {
text = env.fromData(WordCountData.WORDS).name("in-memory-input");
}If an input path is provided from CLI the it will read from the filepath and in case of no input path present this program would read from WordCountData.java file that we are providing.
FileSource.FileSourceBuilder<String> builder =
FileSource.forRecordStreamFormat(
new TextLineInputFormat(), params.getInputs().get());Above code that is Inside of the “if statement” will create a new file source that will read files from a given set of directories.
params.getDiscoveryInterval().ifPresent(builder::monitorContinuously);If a discovery interval is provided, the source will continuously watch the given directories for new files. Again this would be provided as input parameters from CLI.
DataStream<Tuple2<String, Integer>> counts =
text.flatMap(new Tokenizer())
.name("tokenizer")
.keyBy(value -> value.f0)
.sum(1)
.name("counter");The text variable contains the lines read from the source, which are then split into words using a user-defined function “Tokenizer” that you can see in WordCount.java. The tokenizer will output each word as 2-tuple containing (word, 1).
if (params.getOutput().isPresent()) {
counts.sinkTo(
FileSink.<Tuple2<String, Integer>>forRowFormat(
params.getOutput().get(), new SimpleStringEncoder<>())
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withMaxPartSize(MemorySize.ofMebiBytes(1))
.withRolloverInterval(Duration.ofSeconds(10))
.build())
.build())
.name("file-sink");
} else {
counts.print().name("print-sink");
}If output file is specified through cli then results would be written in the file or else it would be printed in the terminal or standard out. Further, FileSinksupports both row-wise as (FileSink.forRowFormat(basePath, rowEncoder) and bulk encoding formats as (FileSink.forBulkFormat(basePath, bulkWriterFactory)). Above, we are using row-encoded format that needs an Encoder (SimpleStringEncoder)that is used for serializing individual rows to the OutputStream of the in-progress part files. Row-encoded format also provided Custom RollingPolicy to override the DefaultRollingPolicy.
RollingPolicy : defines when a given in-progress part file will be closed and moved to the pending and later to a finished state.
.withRolloverInterval : Sets the max time a part file can stay open before having to roll.
.withMaxPartSize: Sets the part size above which a part file will have to roll.
public static final class Tokenizer
implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
// normalize and split the line
String[] tokens = value.toLowerCase().split("\\W+");
// emit the pairs
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<>(token, 1));
}
}
}
}Above is a UDF to implements the string tokenizer that splits sentences into words as a user-defined
1. FlatMapFunction. The function takes a line (String) and splits it into multiple pairs in the
2. form of “(word,1)” ({@code Tuple2<String, Integer>})
Building your Project in IntelliJ
Now that we have 3 class files and pom.xml, we can go ahead and build our project to create the jar file.
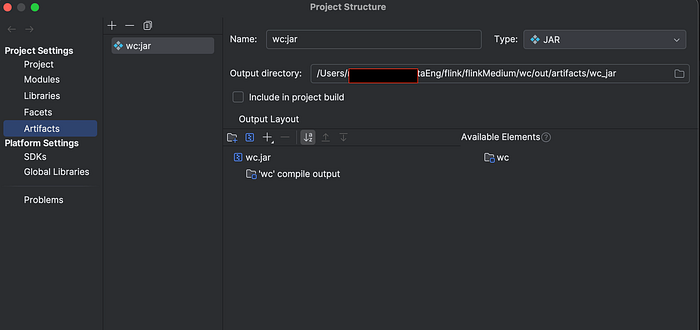
First we will build the artifact, by going to File|Project Structure. You would see screen below. Select Artifacts and click on + to create a new artifact. Select the directory that contains pom.xml file.
Next go on Run|Edit Configuration|Maven . Give it a name and under run give command clean install -U as below
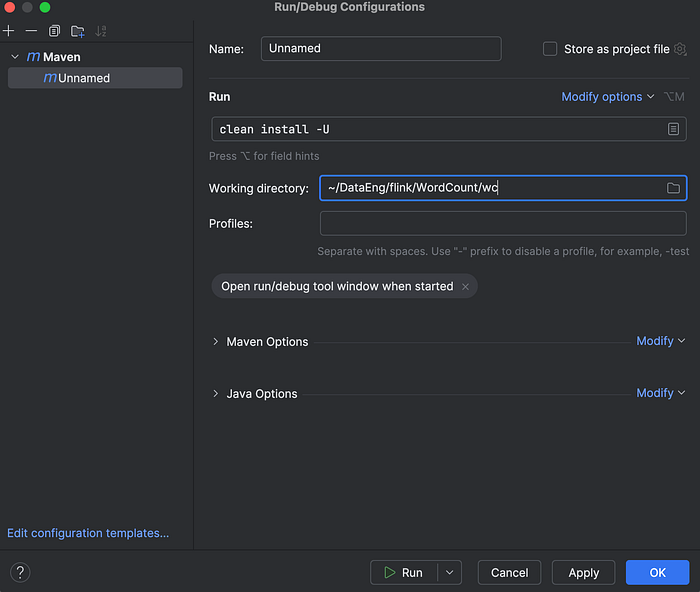
Apply and Run. You will see a target directory gets created with a jar file.
We will be using this jar file to run on flink. Given your flink cluster is already up and running as explained in previous article, we will not submit our job via terminal as below.
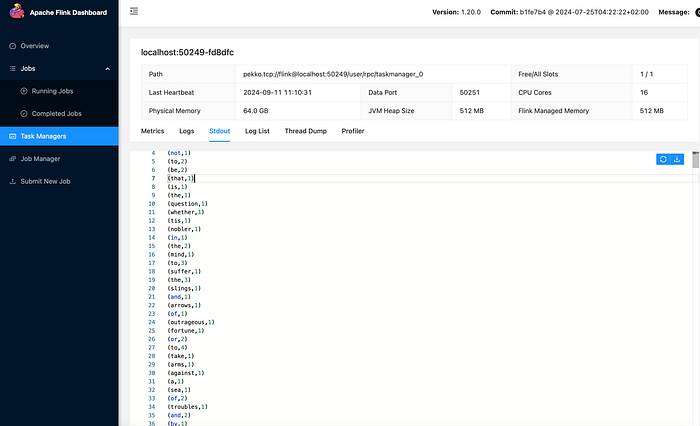
bin/flink run -c p1.WordCount /Users/xxx/DataEng/flink/flinkMedium/wc/target/wc-1.jar --port 9000 --input /Users/xxx/Downloads/StreamingIf you did everything correctly you should see a JobID being printed as below.

You can see above I am providing input through CLI which is a directory location containing files. Since, I did not provide an output, it would be printed on Flink UI as below. In order to get an output generated to a file, providing a filepath by output param can be provided.