- Sep 23, 2025
Data Governance – Implementation in Data Engineering
- DevTechie Inc
- Data Engineering
Data governance in data engineering is the set of principles, policies, and processes that ensure data is managed as a valuable asset. It focuses on ensuring data is secure, private, accurate, and available throughout its lifecycle. For data engineers, governance isn't just about compliance; it's about building robust and reliable data pipelines and architectures that produce trustworthy data.
Core Components of Data Governance
Data governance relies on a few key pillars to be successful. A data engineer's work directly supports these.
Data Quality: This ensures data is accurate, complete, consistent, and timely. Data engineers build pipelines with automated checks, validation rules, and monitoring systems to flag and correct data quality issues at the source. This is a crucial step in preventing bad data from contaminating downstream systems.
Data Security and Privacy: This involves protecting data from unauthorized access, use, or disclosure. Data engineers implement security measures like encryption, access controls (e.g., role-based access), and data masking to protect sensitive information, such as Personally Identifiable Information (PII).
Metadata Management and Data Lineage: Metadata is "data about data," providing context like where data came from, who owns it, and how it was transformed. Data lineage traces the journey of data from its source to its destination. Data engineers are responsible for building systems that automatically capture and track this metadata, creating a transparent and auditable record of the data's entire lifecycle.
Compliance: This involves adhering to regulations such as GDPR, CCPA, or HIPAA. Data engineers ensure data pipelines and storage systems are designed to meet these legal requirements, which often involves specific rules for data handling, retention, and access.
Deep Dive into the core concepts
1. Data Quality
Data quality ensures data is fit for its intended use, and its technical implementation relies on proactive and reactive measures.
-
Data Profiling: This is the process of examining the data from a source and collecting statistics and information about that data. A data engineer uses tools to scan a dataset to find things like:
Value Ranges: What's the min/max value of a numerical column?
Frequency Distributions: How often do certain values appear?
Null Counts: How many records have missing values in a given column?
Data Types: Is a column that should be a date stored as a string?
Schema Consistency: Do schemas match across different sources or tables?
-
Data Validation and Monitoring: Validation is the practice of checking data against predefined rules. Data engineers embed these checks directly into data pipelines.
Schema Validation: Tools like Great Expectations or a simple JSON schema check can be used to ensure the structure of incoming data is correct before it's processed.
Rule-Based Validation: Data engineers write code to enforce business rules, such as "a customer's age must be greater than 18" or "a zip code must conform to a specific format."
Data Observability: This is the proactive monitoring of data pipelines to detect anomalies. For example, setting up alerts if a data freshness metric shows a pipeline hasn't run, or if the number of rows processed suddenly drops by 50%. This helps detect issues before they impact downstream analytics.
2. Data Security and Privacy
This component is all about controlling access and protecting sensitive information. Data engineers are responsible for implementing these technical controls.
Access Controls (IAM): This involves configuring Identity and Access Management (IAM) policies in data platforms (e.g., AWS IAM, Azure Active Directory). A data engineer defines Role-Based Access Control (RBAC), which grants permissions based on a user's job function. For example, a data analyst might have read-only access to customer data, while a data scientist might have read access to a masked version of the same data.
-
Data Encryption: Data engineers implement encryption to protect data both in transit (as it moves through a pipeline) and at rest (while it's stored).
Encryption in Transit: Using secure protocols like TLS/SSL to encrypt data as it's sent between systems (e.g., from a source database to a data warehouse).
Encryption at Rest: Encrypting data on storage media, such as an S3 bucket or a database table. This is often handled at the platform level, but a data engineer configures and manages the encryption keys.
-
Data Masking and Anonymization: These techniques obscure sensitive data to protect privacy while still allowing the data to be used for analytics.
Static Data Masking: Creates a copy of a production dataset with sensitive fields permanently altered (e.g., replacing a customer's name with a random string). This is often used for non-production environments like development or testing.
Dynamic Data Masking: Masks data in real-time as it's queried, so the underlying data remains unchanged but is hidden from unauthorized users. A query to a field like ssn would return XXX-XX-XXXX for a user without proper permissions.
Tokenization: Replaces sensitive data (like a credit card number) with a non-sensitive equivalent called a token. This token can be stored in a less secure environment, while the real data is kept in a highly secure vault.
3. Metadata Management and Data Lineage
This is the technical foundation for understanding data. Data engineers build the systems that collect and present this information.
-
Automated Metadata Extraction: Data engineers build connectors and scripts that automatically pull metadata from various data sources.
Technical Metadata: Information about the data's structure, like table schemas, column names, data types, and file formats. This is extracted directly from databases, data warehouses, and data lakes.
Operational Metadata: Information about how data is processed, such as job run times, success/failure status, and pipeline execution logs. This is collected from orchestration tools like Apache Airflow or Prefect.
-
Data Lineage Tracking: This is the process of mapping the flow of data through a pipeline. It provides a technical audit trail for every piece of data.
Parsing Query Logs: One common technique is to parse SQL query logs to automatically infer dependencies. For example, if a query SELECT * FROM sales_data is used to create a new table daily_revenue_report, a tool can automatically infer that the daily_revenue_report table is a descendant of the sales_data table.
Tool Integration: Data lineage tools integrate with various data platforms to capture lineage at the table and even column level, providing a visual map of the entire data journey.
4. Compliance
Compliance is the application of the above technical components to meet legal and regulatory requirements.
Data Classification and Tagging: Data engineers work with data owners to technically classify data. They apply tags (e.g., PII, PHI) at the table or column level to identify sensitive data. This allows automated policies to be applied, such as not allowing a table tagged "PII" to be shared with an unauthorized team.
Automated Data Retention Policies: Regulations like GDPR require data to be deleted after a certain period. Data engineers implement automated scripts or use platform features to manage the lifecycle of data, ensuring it's automatically archived or deleted according to policy. For example, using a time-to-live (TTL) policy on a database or a data lake to automatically expire old records.
Audit Logging: To prove compliance, data engineers set up detailed audit logs that track who accessed what data, when, and from where. This provides a clear, unalterable record of all data access and modifications, which is crucial for regulatory audits.
Challenges in Implementing Data Governance
1. Cultural and Organizational Resistance
This is often the most significant challenge. People are naturally resistant to change, and data governance can be seen as an extra burden that slows down work. Departments may operate in data silos, hoarding data and resisting sharing it, believing they own it.
Example: At a large retail company, the marketing department has its own customer database, while the sales department uses a separate CRM system. The data is inconsistent, with different fields and update schedules. A data governance initiative aims to create a "single source of truth" for customer data. However, the marketing team resists, fearing they'll lose control over their campaign-specific data and that new, company-wide policies will make their work less agile. This creates an ongoing struggle to integrate data and enforce quality standards.
2. Lack of Executive Sponsorship and Clear Business Value
Data governance is a long-term investment. If senior leadership doesn't fully understand its value, it's difficult to secure the necessary budget and resources. Without a clear link to business objectives, a governance program can be viewed as a cost center rather than a strategic asset.
Example: A financial services firm wants to improve its data quality to comply with new regulations. The IT team proposes a costly data governance program, but the leadership is hesitant to approve the budget because they only see the cost of compliance, not the revenue opportunities. They fail to understand how accurate, trustworthy data could lead to better risk models, more effective fraud detection, and a more personalized customer experience that increases sales.
3. Technical and Complexity Challenges
Modern data ecosystems are highly distributed, with data residing in multiple clouds, on-premises systems, and various applications. This fragmentation makes it difficult to enforce consistent policies.
Siloed Data: Data is scattered across different systems and departments, making it hard to get a unified view.
Legacy Systems: Older systems often lack the modern APIs and tools needed for automated metadata extraction, lineage tracking, and security controls.
Data Volume and Velocity: The sheer amount of data generated, especially from real-time sources, can overwhelm traditional governance methods.
Example: A global manufacturing company has data from its factory floor (IoT sensors), supply chain, and CRM, all stored in separate systems. They want to create a data lineage map to trace a product's journey from raw materials to a customer's hands. However, they discover that sensor data from different factories is stored in different formats and a legacy ERP system has no API for metadata extraction. The sheer effort to manually reconcile and document this data makes the project stall.
4. Poor Data Quality
You can't govern what you don't trust. A lack of good data quality is both a symptom and a cause of poor governance. If data is incomplete, inconsistent, or inaccurate, users will lose confidence and revert to their own, ungoverned data sources.
Example: An e-commerce company wants to personalize its customer recommendations using an AI model. However, the customer data they feed the model is riddled with duplicate records and inconsistent addresses. For example, a single customer may have multiple entries with different spellings of their name or outdated contact information. The AI model's recommendations are wildly inaccurate, leading to a loss in sales and a breakdown of trust in the data team. The company realizes they need to fix their fundamental data quality issues before any advanced analytics can be successful.
Architectural Diagram
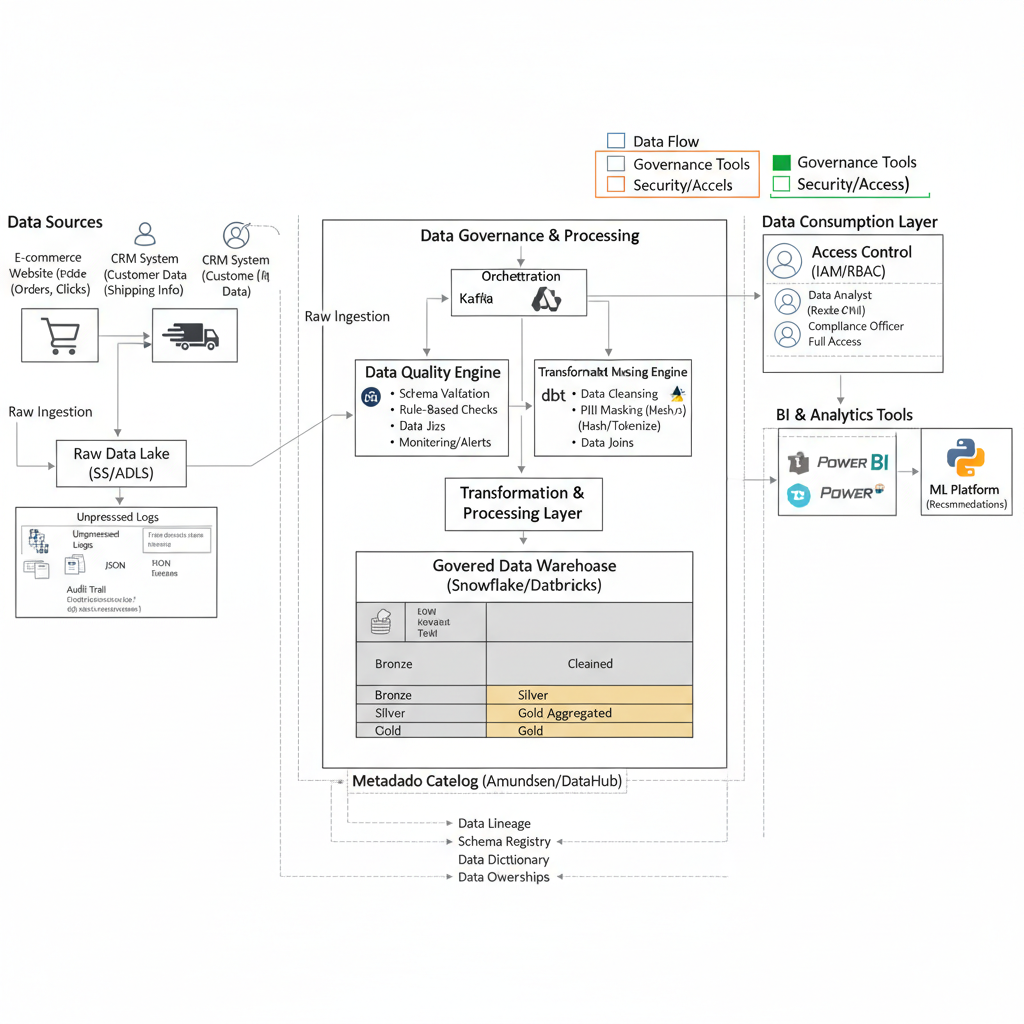
Key metrics to measure data governance success
Measuring the success of a data governance program requires a combination of metrics that track both quantitative results and qualitative improvements. The most effective metrics fall into four key categories: data quality, operational efficiency, regulatory compliance, and data usage.
Data Quality Metrics
These metrics measure how trustworthy and reliable the data is. Improving data quality is a core goal of governance, as it directly impacts business decisions.
Data Accuracy: The percentage of data records that are correct and error-free. You can measure this by comparing a sample of data against a trusted source. For example, a metric could be "98% of customer addresses match a validated postal database."
Data Completeness: The proportion of required fields that are filled in. This is often tracked as a percentage of missing or null values in critical datasets.
Data Consistency: Measures the uniformity of data across different systems. This metric helps identify and resolve conflicting values for the same data point (e.g., a customer's name spelled differently in the sales and marketing databases).
Data Timeliness: The time it takes for data to be updated and made available for use. A key metric is data freshness, which is the lag between when data is generated and when it's accessible in a data warehouse.
Operational Efficiency Metrics
These metrics focus on how a governance program streamlines data-related processes and makes teams more productive.
Time to Access Data: The average time it takes for a user to find, understand, and gain approved access to a specific dataset. A good governance program with a data catalog and clear access policies should significantly reduce this time.
Data Incident Rate: The number of data quality issues, security incidents, or data breaches reported over a given period. A downward trend indicates a more secure and reliable data environment.
Time to Resolve Data Issues: The average time from when a data issue is identified to when it is fully resolved. A shorter resolution time signifies more efficient data stewardship processes.
Cost Savings: This is a direct measure of ROI. You can track cost savings from reduced fines due to non-compliance, avoiding manual data cleanup efforts, or improving data-driven operations (e.g., more effective marketing campaigns with better data).
Regulatory Compliance Metrics
These metrics demonstrate that the organization is adhering to legal and internal policies, which is a major driver for many governance initiatives.
Data Classification Coverage: The percentage of sensitive data assets (e.g., PII, PHI) that have been correctly classified and tagged according to internal policies.
Access Control Adherence: Measures how well access controls are being enforced. This can be tracked by monitoring the number of failed attempts to access sensitive data or the percentage of users with appropriate permissions.
Audit Readiness: The ability to quickly and accurately respond to an audit. Metrics include the time it takes to produce a complete data lineage report or to fulfill a data subject access request (DSAR).
Data Usage and Adoption Metrics
These metrics gauge how effectively the governed data is being utilized by the organization. They show the business value of the program beyond just compliance and quality.
Active Users of the Data Catalog: An increase in users actively searching and using the data catalog indicates a growing trust in and adoption of governed data assets.
Certified vs. Raw Data Usage: Tracks the volume of queries run on "certified" or "gold-standard" datasets compared to raw or uncurated data. A higher ratio of certified data usage shows that users are relying on the single source of truth.
Data Literacy: Measures the overall understanding and awareness of data governance policies among employees. This can be tracked through training completion rates and internal surveys.
Conclusion
A strong data governance framework is no longer a luxury but a fundamental requirement for modern data engineering. By integrating policies, processes, and tools directly into the data pipeline—from ingestion to consumption—data teams can ensure data is not only accessible and high-quality but also secure and compliant. This proactive approach transforms the data engineering function from simply moving data to becoming a strategic enabler of business value, building trust in data assets, and unlocking new opportunities for insights and innovation.