- Oct 3, 2025
CI/CD in Data Engineering
- DevTechie Inc
- Data Engineering
Implementing CI/CD in data engineering introduces a unique set of challenges that differ significantly from traditional software development. Unlike application code, data pipelines operate on dynamic, stateful systems where schema changes, large data volumes, and idempotency must all be carefully managed.
While the principles of automation, version control, and frequent iteration are the same, the "what" being deployed and tested is different, leading to unique challenges.
Difference in CI/CD between Data Pipelines and Application Software like Web Applications

Unique Data Engineering Challenges in CI/CD
Schema Drift and Migration: Data pipelines often involve changing the structure of tables in a data warehouse (the schema). A CI/CD pipeline must include robust steps to safely apply these database migrations (e.g., using tools like Flyway or Liquibase) without causing downtime or data corruption, which is a rare consideration for typical software deployments.
Data Volume for Testing: Running a full test on a large-scale data pipeline would take too long and be too costly. Data CI/CD requires intelligent strategies to use realistic data subsets or synthetic data to validate transformations without sacrificing test integrity or performance.
Idempotency and State Management: Data pipelines often deal with state (what data has already been processed). The deployment process must ensure that rerunning a pipeline after a deployment or rollback is idempotent (produces the same result and doesn't duplicate data), a challenge that is not as critical for stateless web applications.
Scenario: E-Commerce Clickstream Data Pipeline
Let’s take a scenario and imagine a large scale e-commerce clickstream data pipeline that ingest raw user interactions (clicks, views, adds-to-cart) from a high-traffic e-commerce website and transform that data into clean, aggregated metrics for business analysis.
Technologies Used
Ingestion: Kafka (streaming message queue)
Processing: Apache Spark (for ETL transformations)
Storage: Data Lake (e.g., cloud storage like S3, Azure Blob, or a distributed file system)
Deployment: CI/CD pipeline (for deploying the Spark code and schema changes)
Medallion Architecture Flow and Examples
The three-layer Medallion Architecture ensures data quality, consistency, and accessibility across the organization.
1. Bronze Layer (Raw Data)
The Bronze layer is the landing zone for raw, untransformed data. It is immutable—data is stored as-is. In this stage, raw data is streamed from Kafka and saved to the data lake in its original format. This is a minimal transformation layer and highly coupled to the source system.
CI/CD Focus & Unique Steps:
In this stage, Ingestion Validation is pertinent and the focus is on schema inference and source system compatibility. Since this is minimal transformation we can just ensure that the pipeline can handle unexpected source data changes without crashing.
Rollback Strategy:
If things go south, we stop the ingestion, fix the code, restart the job with the broken data partition marked for reprocessing.
2. Silver Layer (Cleansed & Conformed Data)
The Silver layer applies the first set of heavy transformations, focusing on cleansing, standardization, and enrichment. Data here is structured and normalized.
CI/CD Focus & Unique Steps:
Focus here is on data quality assertions (e.g., null counts, uniqueness) and safely executing schema changes (adding/modifying columns). Since we are dealing with processed data here, after processing of a small batch after deployment in staging/pre-production, through data quality checks need to be performed with a certain percentage of production data that represents identified subsets.
Rollback Strategy:
If the outcome is not accurate, the corrupted or inaccurate partition would need to be deleted and code would be rolled back and re-deployed with the older version.
3. Gold Layer (Aggregated & Business-Ready Data)
The Gold layer consists of highly refined, aggregated, and query-optimized tables for specific business use cases (e.g., dashboards, reporting, and ML features).
CI/CD Focus & Unique Steps:
Focus here is on query performance testing and ensuring the new data structure doesn't break downstream reports/ML models. If any aggregation logic is changing, then data quality checks become crucial again as in the silver layer, since the Gold layer tests are often focused on statistical or business metrics derived from Silver.
Rollback Strategy:
Similar to Silver layer
CI/CD in this Pipeline
The CI/CD process ensures reliable deployment of changes to the Spark transformation code and the Medallion schemas.
Code Commit: A data engineer commits a change (e.g., adding a new field to the Silver layer for session duration) to the Git repository.
-
Continuous Integration (CI):
Build: The CI system (e.g., Jenkins, GitLab CI) packages the new Spark/Python code.
Unit Tests: Run unit tests on the transformation logic to ensure the new field is calculated correctly.
-
Data Validation Tests: The most crucial step. The CI pipeline runs the new Silver-layer code against a small set of Test Data (synthetic or a scaled-down snapshot of Bronze data) to ensure:
The pipeline runs without errors.
The new column session_duration is populated as expected.
No pre-existing data quality metrics are violated (e.g., the join with the Users table still works, and the number of nulls in product_id remains within the tolerance).
-
Continuous Delivery/Deployment (CD):
Infrastructure as Code (IaC): The pipeline uses IaC (e.g., Terraform) to apply any necessary schema changes (e.g., adding the new session_duration column) to the tables in the Silver and Gold layers in a staging environment.
Deployment: The new Spark application code is deployed to the staging Spark cluster.
End-to-End Staging Run: A full-scale run of the pipeline is executed in staging, processing a larger (but still non-production) dataset to verify performance and end-to-end data flow before moving to production.
Execution Flow Summary
The developer creates a PR with new Spark code and a new schema migration script.
CI Orchestrator runs → builds code → runs unit tests → runs Data Quality Tests against test data.
Upon successful merge to main, CD Orchestrator is triggered.
CD Orchestrator uses Flyway/dbt to safely apply the new schema migration (add the new column) to the production data warehouse.
CD Orchestrator deploys the new Airflow DAGs to the production Airflow environment.
The new DAG starts its run, now processing production data and writing to the updated schema.
Comparison and Challenges
1. Data Dependency and Data Quality Testing

2. Schema and State Management
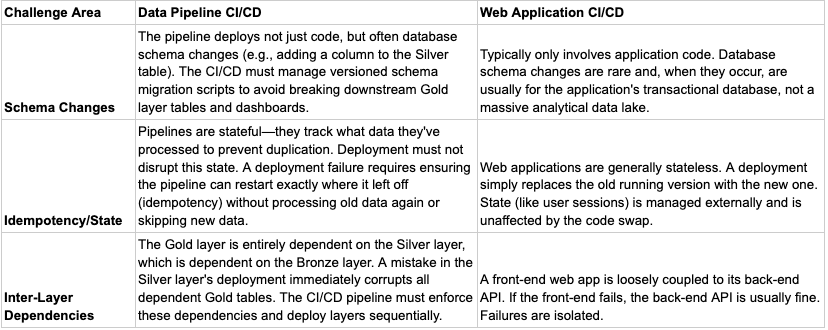
3. Rollback Complexity

Conclusion
To conclude, the application of CI/CD in data engineering fundamentally differs from traditional software deployment due to the centrality, scale, and immutability of data. While both disciplines share the goals of automation, speed, and reliability, the data pipeline introduces unique challenges that shift the focus of the CI/CD pipeline from mere code integrity to data integrity.
The Medallion Architecture (Bronze, Silver, Gold) exemplifies this difference by isolating risk at each stage:
The Bronze Layer CI/CD focuses on ingestion resilience and source compatibility, ensuring raw data is captured immutably.
The Silver Layer CI/CD is the most complex, centering on robust Data Quality (DQ) testing and careful schema migration. A failure here is catastrophic, as the only safe rollback mechanism is deleting the corrupted data partition and re-reading the immutable Bronze source to regenerate the Silver output.
The Gold Layer CI/CD prioritizes query performance and downstream compatibility, validating that new aggregations don't break business reports or ML models.
In essence, a web application CI/CD pipeline tests if the code works, but a data engineering CI/CD pipeline tests if the code works and if the data is correct and safely managed. This data gravity necessitates specialized tools, complex testing (like DQ assertions and performance benchmarks), and rigorous schema management, making data pipeline deployment a high-stakes operation where data correction, not just code reversion, is the ultimate measure of success.