- Nov 6, 2025
Best Practices for Organizing Your DBT Structure
- DevTechie Inc
- Data Engineering
Introduction: The Foundation of Scalability
One of the first few questions a beginner to DBT would ask is, "how should I organize my DBT directories and structure the code?" A well-structured DBT project is crucial for scalability, collaboration, and maintainability. This document details the most widely adopted and effective practices for organizing your DBT codebase.
1. The Core 3-Layer Structure (SIM)
The SIM structure is the most popular approach, separating the models/ directory into three distinct layers based on the complexity and purpose of the transformation.
Staging Layer (stg_)
This layer creates a clean, standardized, and atomic representation of the raw source data.
Only basic transformations take place in this layer involving simple cleanup like renaming the columns, casting to ensure consistent data types, filtering irrelevant data and Adding Source Keys/Surrogate Keys (e.g., a hash of source columns).
Naming Convention: Prefix files with stg_<source>_<table_name> (e.g., stg_mobile_reviews.sql).
Materialization: Almost always a View for maximum freshness and low build cost.
Dependency Rule: Must only reference {{ source(...) }} nodes.
Intermediate (int_)
This layer builds reusable, complex business logic that is shared by multiple final models. This layer reduces complexity in the data marts.
Intermediate transformations like Joins, aggregations, calculating metrics, and re-graining data to a specific, reusable entity. For instance, joining stg_orders and stg_payments to create int_orders_with_details.
Naming Convention: Prefix files with int_<entity>__<description> (e.g., int_customer_lifetime_value.sql).
Materialization: Often Ephemeral (if only referenced once) or a View in a separate schema to isolate the complexity.
Dependency Rule: Must only reference {{ ref(...) }} staging models or other intermediate models. Never reference {{ source(...) }}.
Marts (dim_, fct_)
This layer is the final, business-ready data sets exposed to end-users and BI tools (dashboards, reports, etc.).
Transformations would involve applying business logic, denormalization, and calculating the metrics required for a specific business area. Often follows a dimensional modeling approach.
Naming Convention: Use names grouped by business domain (e.g., orders.sql, dim_customers.sql, fct_sales.sql).
Materialization: Typically Table or Incremental for query performance.
Dependency Rule: Primarily references intermediate models and other mart models. They should be wide, denormalized, and simple to query.
2. Comprehensive Project Structure
The complete DBT project should organize other key assets alongside the models:
DBT_project/
├── models/
│ ├── staging/ # Raw data cleaning & standardization
│ ├── intermediate/ # Transformations used by marts
│ └── marts/ # Final models for analytics
│ ├── finance/ # Group marts by business domain
│ └── marketing/
│
├── snapshots/ # Slowly Changing Dimensions (SCDs)
├── macros/ # Reusable SQL functions or Jinja macros
├── seeds/ # Static CSV files (e.g., country codes, holidays)
├── tests/ # Custom schema tests
└── analyses/ # Ad-hoc analysis queries (not materialized by DBT run)
3. Folder Structure and Naming Conventions
Consistency in naming and organization is vital when scaling.
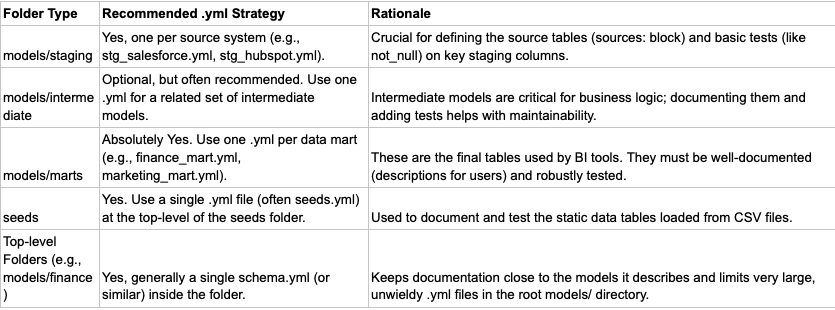
4. .yml File Placement (Documentation & Testing)
It is highly recommended to place .yml files strategically for proper documentation and testing. A single .yml file per logical group of models is the best practice.

5. Code Style and Maintainability
These practices ensure your code is robust, readable, and leverages DBT's core features:
Use ref() and source(): Always use {{ ref('model_name') }} and {{ source('source_name', 'table_name') }}. Never hard-code table names. This is the mechanism DBT uses to build the dependency graph (DAG).
Documentation is Mandatory: Use .yml files to add descriptions to every model, source, and column. This is essential for end-user trust and discoverability (via DBT Docs).
Testing: Apply tests (not_null, unique, accepted_values) to primary keys and critical columns in all models, especially staging and mart models.
Macros for Reusability: Use macros (Jinja functions) for repeated SQL logic (e.g., creating surrogate keys, standardizing timestamps). This keeps your SQL DRY (Don't Repeat Yourself).
Avoid Deeply Chained Views: Limit dependencies between views that are too deep. If the chain becomes Model A (view) -> B (view) -> C (view) -> D (view), query performance degrades significantly. Use table or ephemeral materializations to break the chain and lock in performance where needed.