- Aug 7, 2025
Sentiment Analytics — Hands On Project with Tensorflow and Keras
- DevTechie Inc
Sentiment analysis is the natural language processing (NLP) task which extracts the sentiment (emotions) embedded within a given piece of text.
Let’s do sentiment analysis by building a real-world example in Python and related libraries. Major steps for building a model to do sentiment analysis are:
Step 1: Install required libraries
Step 2: Get (Create) a dataset and load it
Step 3: Pre-process the dataset
Step 4: Train and build the model
Step 5: Use the model i.e. make inference (detect emotion) on unseen data (text in this case)
Step 1: Install Required Libraries
Use !pip installcommand to install in a notebook (Google Colab or Jupyter) cell to install required libraries to do sentiment analysis.
!pip install tensorflow pandas scikit-learnLet’s breakdown each of the libraries.
Keras is a high-level Deep Learning (DL) API (sentiment analysis is a DL task) that allows you to easily build, train, evaluate, and execute all sorts of neural networks by abstracting the intricate details.
Keras was developed by François Chollet and released as an open-source project in March 2015. It quickly gained popularity, owing to its ease of use, flexibility, and beautiful design.
However, Keras depends on low-level APIs for doing the computation involved in DL. Keras can work with different DL libraries such as TensorFlow, Microsoft Cognitive Toolkit (CNTK), and Theano, Apache MXNet, Apple’s Core ML etc.
The workflow is like this:
Your Code → Keras → Theno, CNTK, TensorFlow, Apple Core ML, Java Script, Type Script and PlaidML
Keras now come as a part of Tensorflow beginning with TensorFlow 2.0. It can be referred to as tensorflow.keras (or tf.keras)
TensorFlow is a free and open-source library for working with deep neural network. Tensorflow is most often used with Python, but other languages such as Java, Javascript, TypeScirpt etc. can be used.
Tensorflow is used to create and use models using its API. However, it is a lower-level API than Keras.
It provides a comprehensive ecosystem of tools, libraries, and community resources that enable developers to build and deploy DL models such as the one build in this article (sentiment classifier).
Tensors are the fundamental data structures in TensorFlow, something like vectors and multi-dimensional arrays which are used to hold numerical data representing text, images, audio, video etc. As this data is processed, these vectors (arrays) need to pass from one operation to another and from one layer to another i.e. they are floating/flowing through them, hence the name TensorFlow.
Pandas is a Python library which is used to load data from different file formats like csv, parquet, json etc… into a data structure called DataFrame. The preprocessing capabilities of Pandas are essential for preparing data to be consumed by Deep Learning (DL) libraries. Preparing data may involve converting everything into mathematics form (tensors) to be processed by DL during training.
Scikit-learn is the Python library which provides a wide range of tools such as train_test_split and LabelEncoderfor tasks such as classification, regression, clustering, dimensionality reduction, model selection, and preprocessing.
Step 2: Get (Create) a dataset load it
The dataset used in this article is retrieved form Kaggle.
https://www.kaggle.com/datasets/praveengovi/emotions-dataset-for-nlp
Copy the dataset in the same folder as of your Notebook (codebook)
Load the dataset from your CSV file into data-frame. The head() function displays the first 5 rows of the dataset.
# Load and Explore the Dataset
import pandas as pd
# Load your CSV dataset
df = pd.read_csv("train.csv")
print(df.head())
The dataset has two features — text and emotion. Feature emotion represents the emotion contained in the text feature. This is kind of data where an output (emotion) for each input (text) is given is used for supervised learning. In ML terminology, text is the independent and emotion is the dependent feature/variable.
Step 3: Pre-process the dataset
The DL models work with numerical data and hence feature such as emotion need to be encoded to mathematical representation. Label encoding is one such encoding (preprocessing) technique. The process of label encoding involves assigning a unique integer to each distinct category within a categorical variable. For example, here the emotion feature may have distinct values such as happy, joy, sadness etc. Label encoding may assign 0 to happy, 1 to joy and 2 sadness etc. The fit_transform() method of LableEncoder() class oes this job.
After label encoding the data may look like this
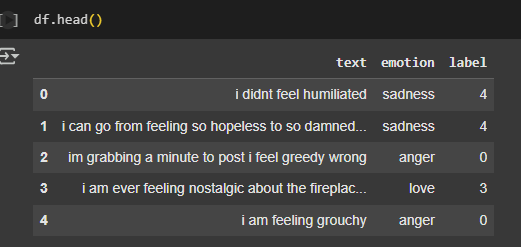
After encoding the dataset needs to be splits into two segments using the train_test_split() function from the sklearn.model_selection package. For ML and DL tasks, you need to divide a dataset into two distinct subsets: a training set and a testing set. Training set is used for training the model and testing set is used to test the model once it is trained.
# Preprocess dataset
from sklearn.model_selection import train_test_split
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.preprocessing import LabelEncoder
# Encode emotion labels into numbers
label_encoder = LabelEncoder()
df['label'] = label_encoder.fit_transform(df['emotion'])
# Split the data
X_train, X_test, y_train, y_test = train_test_split(df['text'], df['label'], test_size=0.2)
# Tokenize the text
tokenizer = Tokenizer(num_words=5000, oov_token="<OOV>")
tokenizer.fit_on_texts(X_train)
# Convert text to sequences and pad them
X_train_seq = tokenizer.texts_to_sequences(X_train)
X_test_seq = tokenizer.texts_to_sequences(X_test)
X_train_pad = pad_sequences(X_train_seq, maxlen=100, padding='post')
X_test_pad = pad_sequences(X_test_seq, maxlen=100, padding='post')Keras’ Tokenizer class breaks down the text into smaller units called tokens. The token can be a word, sub-word and character groups. Further, tokens are assigned a unique integer for processing. fit_on_texts() and text_to_sequences() together do this job of vocabulary building. fit_on_texts() works with word frequency, meaning the most frequent words get the lowest integer values (e.g., 1, 2, 3, etc.), with 0 often reserved for padding.
Then, texts_to_sequences(X_train) transforms the text string into a sequence of integers. Each integer in the sequence corresponds to the index of a word in the vocabulary that the Tokenizer learned during the fit_on_texts()step.
The num_words parameter in the Keras Tokenizer specifies the maximum number of words to keep in the vocabulary. You can configure the tokenizer to handle words not present in its built vocabulary. This is typically done by assigning a special token (“<OOV>”) ID to such words.
Neural networks require fixed-size inputs, but text sequences may be of varying lengths. The pad_sequences() function standardizes the length of text sequences. Padding can be done at either end i.e. pre and post, maxlen argument defines the standard length of the text sequences to be processed by neural networks.
Step 4: Train and build the model
Keras has different kinds of API to build models. Sequential API is used to build sequential neural network (DL) models where the layers are stacked. Input data flows from input layer (first layer) to output layer (last layer) processed by each layer in between. Each layer takes data from its previous one and feeds to the next layer after processing. Another kind of API in Keras is a Functional API which is used to create complex neural networks.
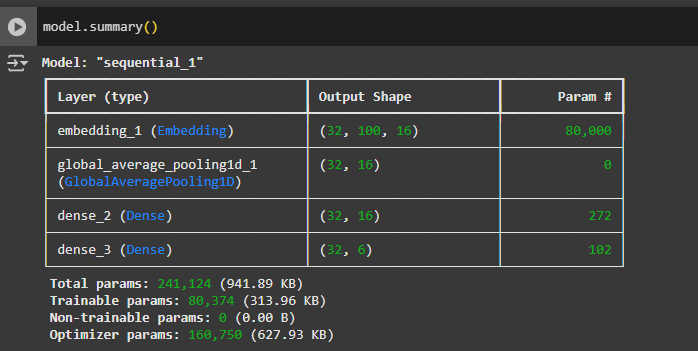
This example has defined three distinct types of layers — Embedding, GlobalAveragePooling1D, Dense. Let’s understand them.
# Build the Model with Keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, GlobalAveragePooling1D, Dense
model = Sequential([
Embedding(input_dim=5000, output_dim=16),
GlobalAveragePooling1D(),
Dense(16, activation='relu'),
Dense(len(df['label'].unique()), activation='softmax')
])Embedding in NLP is the vector representation of the sequence of tokens (words) to capture semantic relationships between tokens. Words with similar meanings tend to have similar embedding vectors. Hence, embedding is the first layer since it takes text sequences and creates embeddings.
Embedding is likely to be first layer in tasks such as text classification, sentiment analysis, or recommendation systems.
The argument input_dim defines the size of the vocabulary, i.e., the total number of unique categories or words to be embedded (tokenizer learned) and output_dim defines the size of the dense embedding vector for each word. Each word will be represented by a 16-dimensional vector. For example, after embedding a 5-word (token) text is represented as 5 x 16 vector (matrix).
The GlobalAveragePooling layer in Keras performs global average pooling over the output of embeddig layer. Here it takes all the 16-dimensional vectors and calculates the average of each dimension. It effectively flattens the sequence into a single 16-dimensional vector (dimensionality reduction). This results in a fixed-length output vector which summarizes the information from the entire sequence into a single vector per feature.
Next is the hidden dense layer (fully connected layer) which performs a matrix multiplication between the input data and a weight matrix with the help of different activation functions, here ReLU is used. Rectified Linear Unit (ReLU) is a popular choice for hidden layers because it introduces non-linearity i.e. it allows the model to learn complex relationships within data and helps mitigate the vanishing gradient problem.
The last layer is also a dense layer with the softmax activation function. This outputs the class of the emotion for the text (sentence). The number of outputs (or number of neurons) is dynamically set to the number of unique classes for the emotion feature via len(df[‘label’].unique().
We can summarize it as — the model takes integer-encoded sequences as input, converts them into dense embeddings, pooling the embeddings to fixed-size representation, and then passes it through two dense layers to classify the input into one of the emotion categories.
Overall model architecture can be seen via model.summary()
# Compile and Train
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(X_train_pad, y_train, epochs=20, validation_data=(X_test_pad, y_test))After defining the model architcture, the compile() method configures the training (learning) parameters of the model. Training requires — loss function, optimizer. Optimizer adjusts the weights and biases of the neural network (especially dense layer) during training to minimize the loss function. Loss function quantifies this adjustment by comparing the model predictions to the actual target values (label feature). Some popular loss functions are categorical_crossentropy, sparse_categorical_crossentropy, mse (mean squared error).
The fit() begins the actual training of the model on the training data. here training happens for 20 epochs (iterations). With each epoch the model is minimizing the loss and improving accuracy.

Step 5: Use model to predict sentiment
# Predict Emotions for New Text
def predict_emotion(text):
seq = tokenizer.texts_to_sequences([text])
pad = pad_sequences(seq, maxlen=100)
pred = model.predict(pad)
emotion = label_encoder.inverse_transform([pred.argmax()])[0]
return emotion
# Try it!
print(predict_emotion("I am feeling happy after watching movie"))
The function predict_emotion(text) is a function which predicts the emotion for the input text. It follows the same path as the model building. It first tokenizes the text, then convert it into a sequence, padding the sequence before feeding it to the model for determining the sentiment of the text.
The label_encoder.inverse_transform([pred.argmax()])[0] is used to convert the model’s numerical prediction back into the original emotion label (string).
The model predicts the probabilities (pred) of each type of emotion (class) as in the dataset i.e. number of different values of label feature, for the given text. Since, we need to predict a single emotion (class) for the text, argmax() finds the index of the class with the highest probability.
The LabelEncoder object, which was used earlier to convert emotions (string labels) to integers, is now used in reverse. inverse_transform() takes a list of integers and converts them back to their original string labels.
Since inverse_transform returns a list (even if there’s only one prediction), [0] is used to extract the first element from that list, giving us the final emotion.
The output for the text “I am feeling happy after watching movie” is “joy”